Deep Learning ideas that have stood the test of time
Deep Learning is such a fast-moving field and the huge number of research papers and ideas can be overwhelming. The goal of this post is to review ideas that have stood the test of time. These ideas, or improvements of them, have been used over and over again. They’re known to work.
If you were to start in Deep Learning today, understanding and implementing each of these techniques would probably give you an excellent foundation for understanding recent research and working on your own projects. Working through papers in historical order is also a useful exercise to understand where the current techniques come from and why they were invented in the first place.
A rather unique aspect of Deep Learning is that its application domains (Vision, Natural Language, Speech, RL, etc) share the majority of techniques. For example, someone who has worked in Deep Learning for Computer Vision his whole career could quickly become productive in NLP research. The specific network architectures may differ, but the concepts, approaches and code are mostly the same. I will try to present ideas from various fields, but there are a few caveats about this list:
- My goal are not in-depth explanations or code examples for these techniques. It’s not possible to summarize long complex papers into a single paragraph. Instead, I will give a brief overview of each technique, its historical context, and links to papers and implementations. If you want to learn more, I recommend trying to re-produce some of these paper results from scratch in PyTorch without using existing code bases or high-level libraries.
- The list is biased towards my own knowledge and the fields I am familiar with. There are many exciting subfields that I don’t have exposure to. I will stick to what most people would consider the popular mainstream domains of Vision, Natural Language, Speech, and Reinforcement Learning / Games.
- I will only discuss research that has official or semi-official open source implementations that are known to work. Some research isn’t easily reproducible because it involves huge engineering challenges, for example DeepMind’s AlphaGo or OpenAI’s Dota 2 AI, so I won’t highlight it here.
- Some choices are arbitrary. Sometimes similar techniques are published at around the same time. The goal of this post is not be a comprehensive review, but to to expose someone new to the field to a cross-section of ideas that cover a lot of ground. For example, there may be hundreds of GAN variations, but to understand the general concept of GANs, it really doesn’t matter which one you study.
2012 - Tackling ImageNet with AlexNet and Dropout #
Papers
- [ImageNet Classification with Deep Convolutional Neural Networks]
- [Improving neural networks by preventing co-adaptation of feature detectors]
- [One weird trick for parallelizing convolutional neural networks]
Implementations
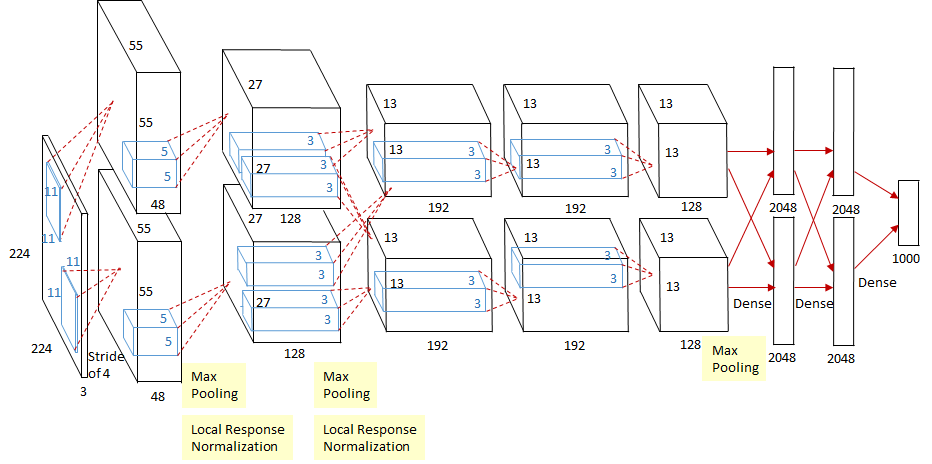
AlexNet is often considered the algorithm responsible for the recent boom in Deep Learning and Artificial Intelligence research. It is a Deep Convolutional Neural Network based on the earlier LeNet developed by Yann LeCun. AlexNet beat previous methods at classifying images from the ImageNet dataset by a significant margin through a combination of GPU power and algorithmic advances. It demonstrated that neural networks actually work! AlexNet was also one of the first times Dropout [Improving neural networks by preventing co-adaptation of feature detectors] was used, which has since become a crucial component for improving the generalization ability of all kinds of Deep Learning models.
The architecture used by AlexNet, a sequence of Convolutional layers, ReLU nonlinearity, and max-pooling, became the accepted standard that future Computer Vision architectures would extend and built upon. These days, software libraries such as PyTorch are so powerful that AlexNet can be implemented in only a few lines of code. Note that many implementations of AlexNet, such as those linked above, use the slight variation of the network described in [One weird trick for parallelizing convolutional neural networks] .
2013 - Playing Atari with Deep Reinforcement Learning #
Papers
Implementations
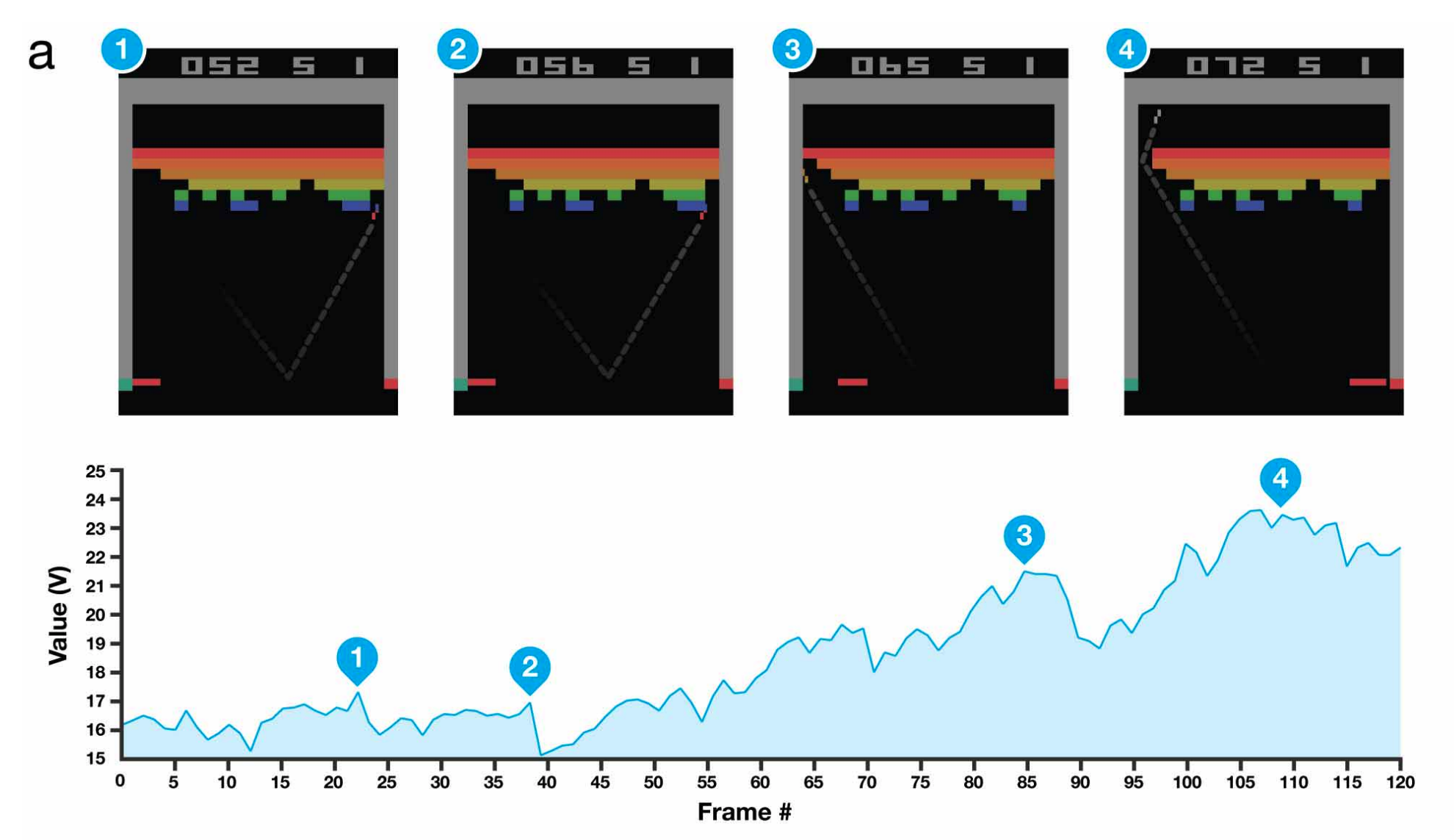
Building on top of the breakthroughs in image recognition and GPUs, a team at DeepMind managed to train a network to play Atari Games from raw pixel inputs. The same neural network architecture learned to play seven different games without being told any game-specific rules, demonstrating the generality of the approach.
Reinforcement Learning differs from Supervised Learning, such as image classification, in that an agent must learn maximize to the sum of rewards over multiple time steps, such as winning a game, instead of just predicting a label. Because the agent interacts directly with the environment and each action affects the next, the training data is not independent and identically distributed (iid), which can make training of other Machine Learning models unstable. This was solved by using techniques such as experience replay [Self-Improving Reactive Agents Based on Reinforcement Learning, Planning and Teaching] .
While there was no obvious algorithmic innovation that made this work, the research cleverly combined existing techniques, convolutional neural networks trained on GPUs and experience replay, with a few data processing tricks to achieve impressive results that most people did not expect. This gave people confidence in extending Deep Reinforcement Learning techniques to tackle even more complex tasks such as Go, Dota 2, Starcraft 2, and others.
Atari Games [The Arcade Learning Environment: An Evaluation Platform for General Agents] have since become a standard benchmark in Reinforcement Learning research. The initial approach only solved (beat human baselines on) seven games, but over the coming years advances built on top of these ideas would start beating humans on an ever increasing number of games. One particular game, Montezuma’s Revenge, was famous for requiring long-term planning and was considered to be among the most difficult to solve. It was only recently [Agent57: Outperforming the Atari Human Benchmark] [First return then explore] that techniques managed to beat human baselines on all 57 games.
2014 - Encoder-Decoder Networks with Attention #
Papers
- [Sequence to Sequence Learning with Neural Networks]
- [Neural Machine Translation by Jointly Learning to Align and Translate]
Implementations
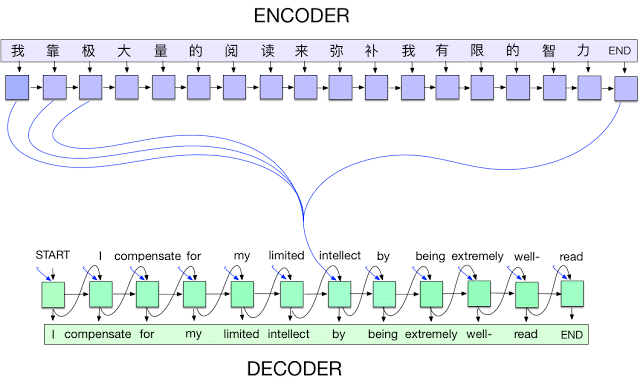
So far, Deep Learning’s impressive results have largely been on vision-related tasks and were driven by Convolutional Neural Networks. While the NLP community had success with Language Modeling and Translation using LSTM networks [Long Short-Term Memory] and Encoder-Decoder architectures [Sequence to Sequence Learning with Neural Networks] , it was not until the invention of the attention mechanism [Neural Machine Translation by Jointly Learning to Align and Translate] that things started to work spectacularly well.
When processing language, each token, which could be a character, a word, or something in between, is fed into a recurrent network, such as an LSTM, which maintains a kind of memory of previously processed inputs. In other words, a sentence is very similar to a time series with each token being a time step. Such recurrent models tended to have difficulty dealing with dependencies over long time horizons. When they process a sequence, they would easily “forget” earlier inputs because the gradients needed to propagate through many time steps. Optimizing these models with gradient descent was hard.
The new attention mechanism helped alleviate the problem. It gave the network an option to adaptively “look back” at earlier time steps by introducing shortcut connections. These connections allowed the network to decide which inputs are important when producing a specific output. The canonical example is translation: When producing an output word, it typically maps to one or more specific input words.
2014 - Adam Optimizer #
Papers
Implementations
Neural networks are trained by minimizing a loss function, such as the average classification error, using an optimizer. The optimizer is responsible for figuring out how to adjust the parameters of the network to make it learn the objective. Most optimizers are based on variations of Stochastic Gradient Descent (SGD). However, many of these optimizers contain tunable parameters such as a learning rate themselves. Finding the right settings for a specific problem not only reduces training time, but can also lead to better results due to finding a better local minimum of the loss function.
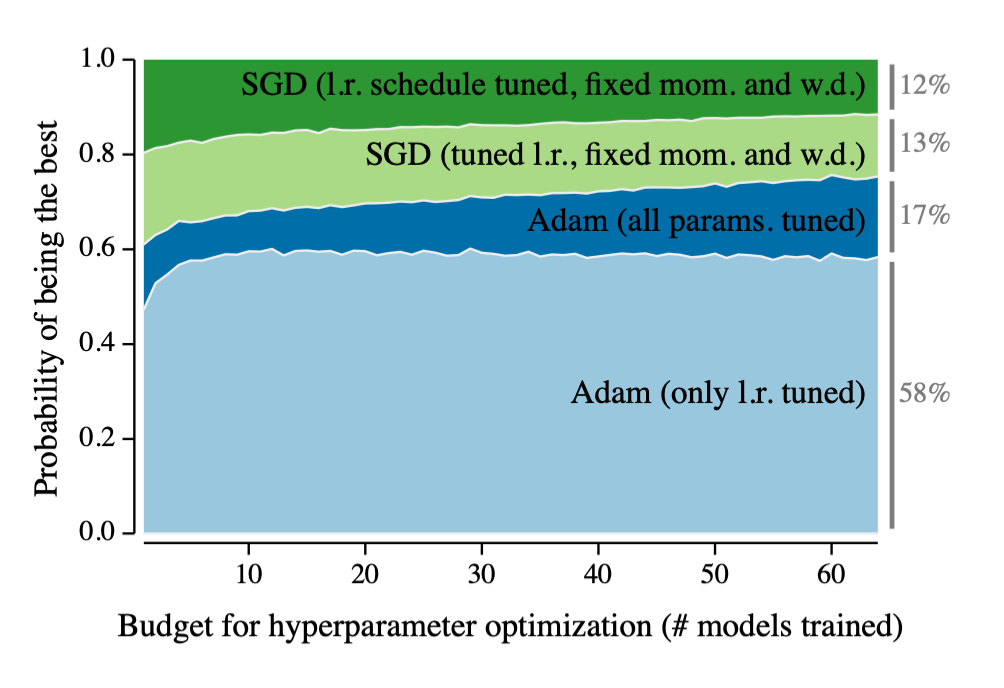
Big research labs often run expensive hyperparameter searches with complex learning rate schedules to get the best out of simple but hyperparameter-sensitive optimizers such as SGD. When they beat existing benchmarks, it sometimes was a result of spending a lot of money to tune the optimizer. Such details weren’t usually mentioned in published research papers. Researchers who did not have the same budget to optimize their optimizer were stuck with worse results.
The Adam optimizer proposed to use the first and second moments of the gradients to automatically adapt the learning rate. The result turned out to be quite robust and less sensitive to hyperparameter choices. In other words, Adam often just works and did not require the same extensive tuning as other optimizers [Optimizer Benchmarking Needs to Account for Hyperparameter Tuning] . While an extremely well-tuned SGD could still get slightly better results, Adam made research more accessible. If something didn’t work, you knew it was unlikely to be the fault of a badly tuned optimizer.
2014/2015 - Generative Adversarial Networks (GANs) #
Papers
- [Generative Adversarial Networks]
- [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks]
Implementations

The goal of generative models, such as variational autoencoders, is to create realistic-looking data samples, like these images of people’s faces you’ve probably seen somewhere. Because they have to model the full data distribution (many pixels!), and not just classify cats or dogs as a discriminative model would, such models are quite difficult to train. Generative Adversarial Networks, or GANs, are one such type of model.
The basic idea behind GANs is to train two networks in tandem - a generator and a discriminator. The generator’s goal is to produce samples that fool the discriminator, which is trained to distinguish between real and generated images. Over time, the discriminator will become better at recognizing fakes, but the generator will also become better at fooling the discriminator and thus produce ever more realistic-looking samples. The very first iteration of GANs produced blurry low-resolution images and was quite unstable to train. Over time, variation and improvements such as DCGAN [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks] , Wasserstein GAN [Wasserstein GAN] , CycleGAN [Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks] , StyleGAN (v2) [Analyzing and Improving the Image Quality of StyleGAN] , and many others have built upon this idea to produce high-resolution photorealistic images and videos.
2015 - Residual Networks (ResNet) #
Papers
Implementations
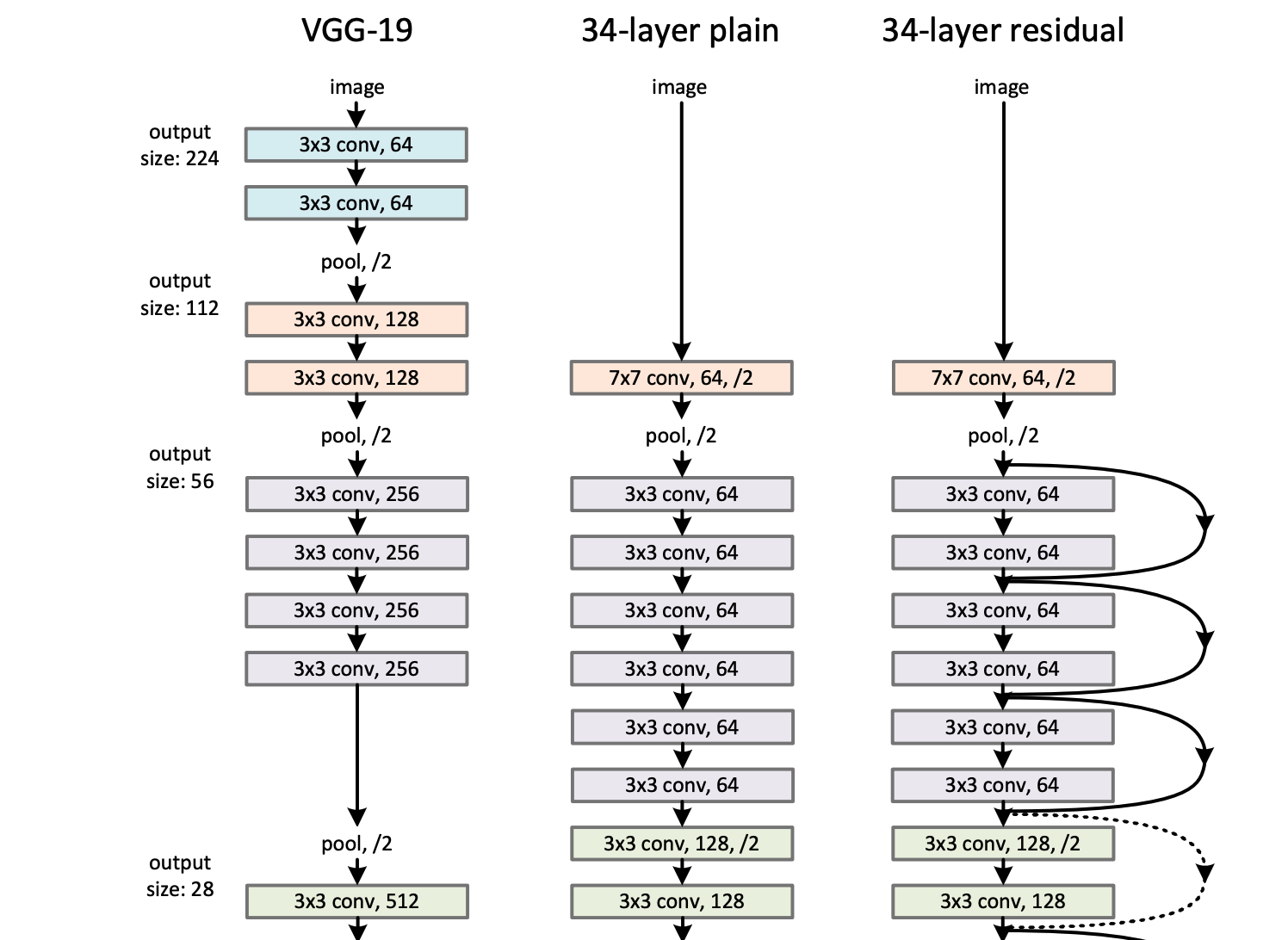
Researchers built on top of the AlexNet breakthrough, inventing better-performing architectures based on Convolutional Neural Networks such as VGGNet [Very Deep Convolutional Networks for Large-Scale Image Recognition] , Inception [Going Deeper with Convolutions] , and many others. ResNet was the next iteration in this rapid series of advances. To this day, ResNet variations are commonly used as a baseline model architecture for all kinds of tasks and as buildings blocks for more complex architectures.
What made ResNet special, apart from it winning first place in the ILSVRC 2015 classification challenge, was its depth compared to other network architectures. The deepest network presented in the paper had 1,000 layers and still performed well, though slightly worse than its 101 and 152 layer counterparts on the benchmark tasks. Training such deep networks was a challenging optimization problem due to the vanishing gradients, which also appeared in sequence models. Not many researchers believed that training such extremely deep networks could lead to stable results.
ResNet used identity shortcut connections that help the gradient flow. One way to interpret these connections is that ResNet only needs to learns “deltas” from one layer to another, which is often easier than learning full transformations. Such identity connections were a special case of the connections proposed in Highway Networks [Training Very Deep Networks] , which in turn were inspired by the gating mechanisms LSTMs used.
2017 - Transformers #
Papers
Implementations
- PyTorch: Sequence-to-Sequence Modeling with nn.Transformer and TorchText
- Tensorflow: Transformer model for language understanding
- HuggingFace Transformers Library
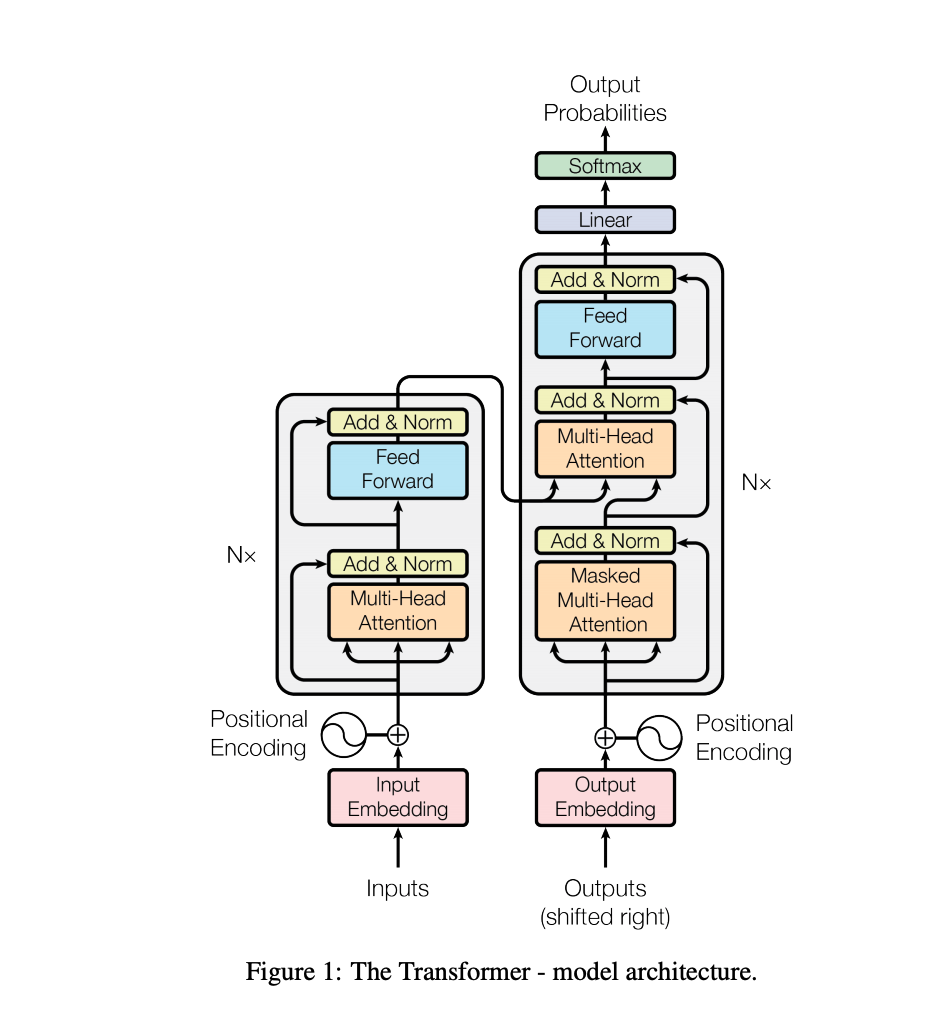
Sequence-to-Sequence models with attention (described earlier in this post) worked quite well, but they had a few drawbacks due to their recurrent nature that required sequential computation. They were difficult to parallelize because they processed the input one step at a time. Each time step depends on the previous one. This made it difficult to scale them to very long sequences. Even with their attention mechanism, they still struggled with modeling complex long-range dependencies. Most of the “work” seemed to be done in the recurrent layers.
Transformers solved these issues by completely removing the recurrence and replacing it with multiple feed-forward self-attention layers, processing all inputs in parallel and producing relatively short (= easy to optimize with gradient descent) paths between inputs and outputs. They are fast to train, easy to scale, and can process a lot more data. To tell the network about the order of the inputs, which was implicit in the recurrent model, Transformers used positional encodings [Convolutional Sequence to Sequence Learning] - to learn more about how exactly transformers work, which can be a bit confusing at first, I recommend this illustrated guide.
To say that Transformers worked better than almost anyone expected would be an understatement. Over the next few years, they would become the standard architecture for the vast majority of NLP and other sequence tasks, and also make their way into architectures for computer vision.
2018 - BERT and fine-tuned NLP Models #
Papers
Implementations
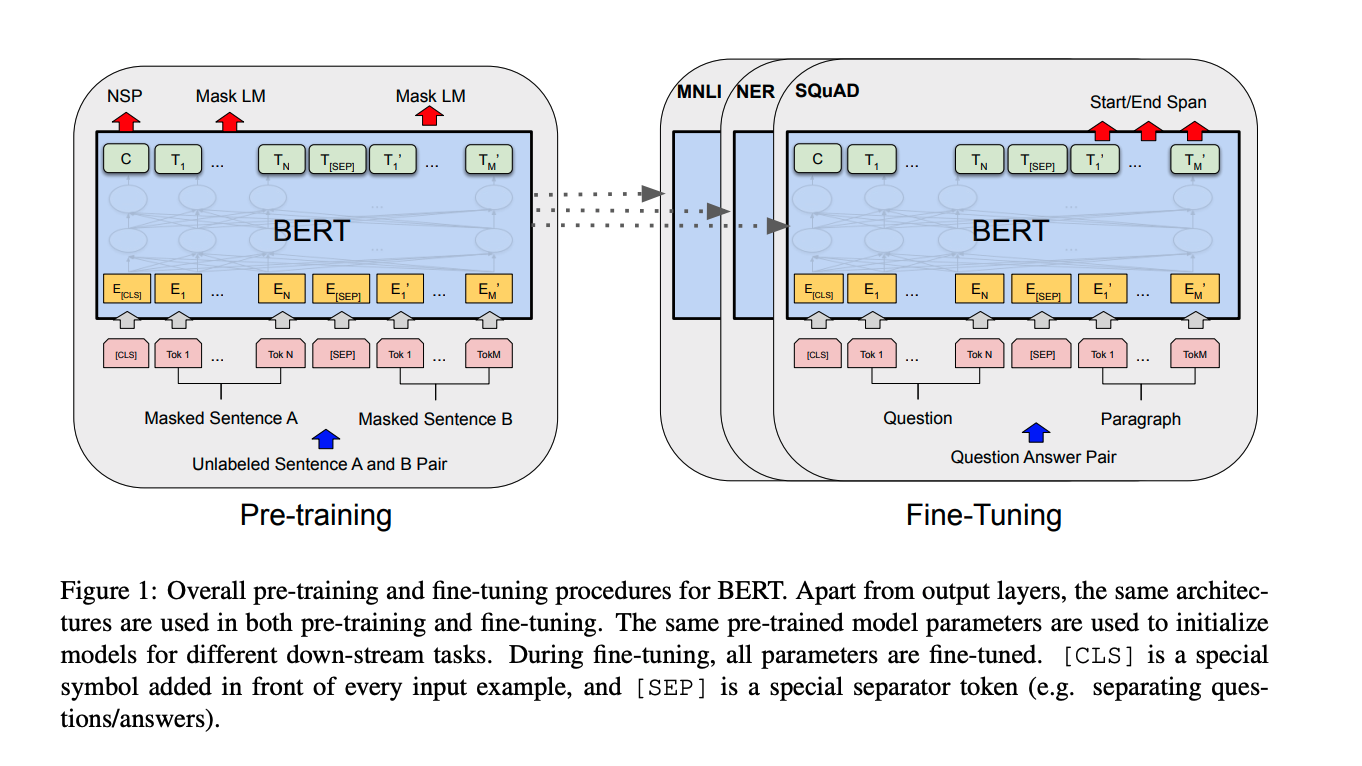
Pre-training refers to training a model to perform some task and then using the learned parameters as an initialization to learn a related task. This makes intuitive sense - a model that has learned to classify images as cats or dogs should have learned something general about images and furry animals. When this model is fine-tuned to classify foxes, we would expect it to do better than a model that must learn from scratch. Similarly, a model that has learned to predict the next word in a sentence should have learned something general about human language patterns. We would expect it to be a good initialization for related tasks like translation or sentiment analysis.
Pre-training and fine-tuning had been used successfully in both Computer Vision and NLP, but while it had been standard in vision for a long time, making it work well in NLP seemed more challenging. Most state-of-the-art results still came from fully supervised models. With the advent of transformers, researchers finally started to make pre-training work, resulting in approaches such as ELMo [Deep contextualized word representations] , ULMFiT [Universal Language Model Fine-tuning for Text Classification] and OpenAI’s GPT.
BERT was the latest of such developments and many consider it to have started a new era of NLP research. Instead of being pre-trained on predicting the next word, as most other models, it was pre-trained on predicting masked (intentionally removed) words anywhere in the sentence, and whether two sentences are likely to follow each other. Note that these tasks don’t require labeled data. It can be trained on any text, a whole lot of it! This pre-trained model, which likely has learned some general properties about language, can then be fine-tuned to solve supervised tasks, such as question answering or sentiment prediction. BERT performed incredibly well across a wide variety of tasks. Companies such as HuggingFace made it easy to download and fine-tune BERT-like models for any NLP task. Since then, BERT has been built upon by advances such as XLNet [XLNet: Generalized Autoregressive Pretraining for Language Understanding] and RoBERTa [RoBERTa: A Robustly Optimized BERT Pretraining Approach] and ALBERT [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations] .
2019-2020 - BIG Language Models, Self-Supervised Learning? #
The clearest trend throughout the history of Deep Learning is perhaps that of the bitter lesson. Algorithmic advances and better parallelization (= more data) and more model parameters often win over smarter techniques. This trend seems to continue well into 2020 where GPT-3, a huge 175 billion parameter language model by OpenAI, shows unexpectedly good generalization abilities despite its simple training objective and standard architecture.
Playing into the same trend are approaches such as contrastive self-supervised learning, e.g. SimCLR, that make better use of unlabeled data. As models become bigger and faster to train, techniques that can make efficient use of the huge set of unlabeled data on web, and learn general-purpose knowledge that which can transferred to other tasks, are becoming more valuable and widely adopted.
Honorary mentions #
- Distributed Representations of Words and Phrases and their Compositionality (2013)
- Speech recognition with deep recurrent neural networks (2013)
- Very Deep Convolutional Networks for Large-Scale Image Recognition (2014)
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (2015)
- Rethinking the Inception Architecture for Computer Vision (2015)
- WaveNet: A Generative Model for Raw Audio (2016)
- Mastering the game of Go with deep neural networks and tree search (2016)
- Neural Architecture Search with Reinforcement Learning (2017)
- Mask R-CNN (2017)
- Dota 2 with Large Scale Deep Reinforcement Learning (2017-2019)
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks (2018)
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (2019)