AI and Deep Learning in 2017 – A Year in Review
The year is coming to an end. I did not write nearly as much as I had planned to. But I’m hoping to change that next year, with more tutorials around Reinforcement Learning, Evolution, and Bayesian Methods coming to WildML! And what better way to start than with a summary of all the amazing things that happened in 2017? Looking back through my Twitter history and the WildML newsletter, the following topics repeatedly came up. I’ll inevitably miss some important milestones, so please let me know about it in the comments!
Reinforcement Learning beats humans at their own games #
The biggest success story of the year was probably AlphaGo (Nature paper), a Reinforcement Learning agent that beat the world’s best Go players. Due to its extremely large search space, Go was thought to be out of reach of Machine Learning techniques for a couple more years. What a nice surprise!
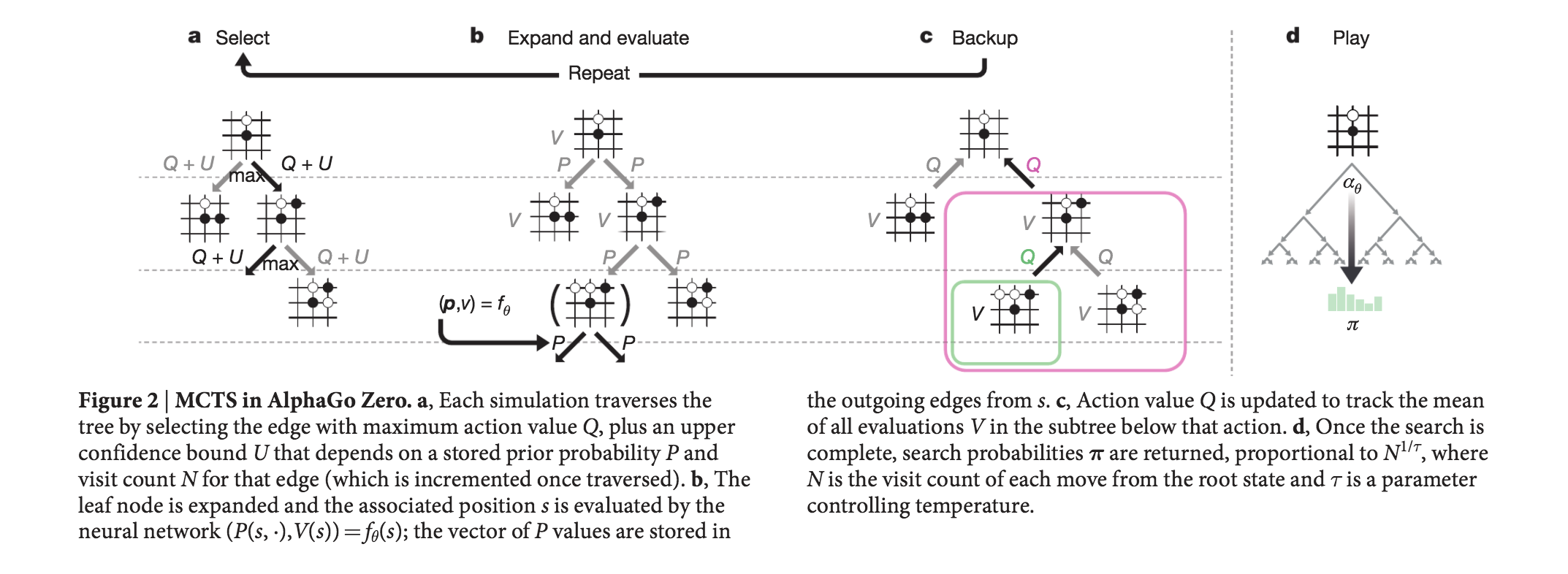
The first version of AlphaGo was bootstrapped using training data from human experts and further improved through self-play and an adaptation of Monte-Carlo Tree Search. Soon after, AlphaGo Zero (Nature Paper) took it a step further and learned to play Go from scratch, without human training data whatsoever, using a technique simultaneously published in the Thinking Fast and Slow with Deep Learning and Tree Search paper. It also handily beat the first version of AlphaGo. Towards the end of the year, we saw yet another generalization of the AlphaGo Zero algorithm, called AlphaZero, which not only mastered Go, but also Chess and Shogi, using the exact same techniques. Interestingly, these programs made moves that surprised even the most experienced Go players, motivating players to learn from AlphaGo and adjusting their own play style accordingly. To make this easier, DeepMind also released an AlphaGo Teach tool.
But Go wasn’t the only game where we made significant progress. Libratus (Science paper), a system developed by researchers from CMU, managed to beat top Poker players in a 20-day Heads-up, No-Limit Texas Hold’em tournament. A little earlier, DeepStack, a system developed by researchers from Charles University, The Czech Technical University, and the University of Alberta, became the first to beat professional poker players. Note that both of these systems played Heads-up poker, which is played between two players and a significantly easier problem than playing at a table of multiple players. The latter will most likely see additional progress in 2018.
The next frontiers for Reinforcement Learning seem to be more complex multi-player games, including multi-player Poker. DeepMind is actively working on Starcraft 2, releasing a research environment, and OpenAI demonstrated initial success in 1v1 Dota 2, with the goal of competing in the the full 5v5 game in the near future.
Evolution Algorithms make a Comeback #
For supervised learning, gradient-based approaches using the back-propagation algorithm have been working extremely well. And that isn’t likely to change anytime soon. However, in Reinforcement Learning, Evolution Strategies (ES) seem to be making a comeback. Because the data typically is not iid (independent and identically distributed), error signals are sparser, and because there is a need for exploration, algorithms that do not rely on gradients can work quite well. In addition, evolutionary algorithms can scale linearly to thousands of machines enabling extremely fast parallel training. They do not require expensive GPUs, but can be trained on a large number (typically hundreds to thousands) of cheap CPUs.
Earlier in the year, researchers from OpenAI demonstrated that Evolution Strategies can achieve performance comparable to standard Reinforcement Learning algorithms such as Deep Q-Learning. Towards the end of the year, a team from Uber released a blog post and a set of five research papers, further demonstrating the potential of Genetic Algorithms and novelty search. Using an extremely simple Genetic Algorithm, and no gradient information whatsoever, their algorithm learns to play difficult Atari Games. Here’s a video of the GA policy scoreing 10,500 on Frostbite. DQN, AC3, and ES score less than 1,000 on this game.
WaveNets, CNNs, and Attention Mechanisms #
Google’s Tacotron 2 text-to-speech system produces extremely impressive audio samples and is based on WaveNet, an autoregressive model which is also deployed in the Google Assistant and has seen massive speed improvements in the past year. WaveNet had previously been applied to Machine Translation as well, resulting in faster training times that recurrent architectures.
The move away from expensive recurrent architectures that take long to train seems to be larger trend in Machine Learning subfields. In Attention is All you Need, researchers get rid of recurrence and convolutions entirely, and use a more sophisticated attention mechanism to achieve state of the art results at a fraction of the training costs.
The Year of Deep Learning frameworks #
If I had to summarize 2017 in one sentence, it would be the year of frameworks. Facebook made a big splash with PyTorch. Due to its dynamic graph construction similar to what Chainer offers, PyTorch received much love from researchers in Natural Language Processing, who regularly have to deal with dynamic and recurrent structures that hard to declare in a static graph frameworks such as Tensorflow.
Tensorflow had quite a run in 2017. Tensorflow 1.0 with a stable and backwards-compatible API was released in February. Currently, Tensorflow is at version 1.4.1. In addition to the main framework, several Tensorflow companion libraries were released, including Tensorflow Fold for dynamic computation graphs, Tensorflow Transform for data input pipelines, and DeepMind’s higher-level Sonnet library. The Tensorflow team also announced a new eager execution mode which works similar to PyTorch’s dynamic computation graphs.
In addition to Google and Facebook, many other companies jumped on the Machine Learning framework bandwagon:
- Apple announced its CoreML mobile machine learning library.
- A team at Uber released Pyro, a Deep Probabilistic Programming Language.
- Amazon announced Gluon, a higher-level API available in MXNet.
- Uber released details about its internal Michelangelo Machine Learning infrastructure platform.
And because the number of framework is getting out of hand, Facebook and Microsoft announced the ONNX open format to share deep learning models across frameworks. For example, you may train your model in one framework, but then serve it in production in another one.
In addition to general-purpose Deep Learning frameworks, we saw a large number of Reinforcement Learning frameworks being released, including:
- OpenAI Roboschool is an open-source software for robot simulation.
- OpenAI Baselines is a set of high-quality implementations of reinforcement learning algorithms.
- Tensorflow Agents contains optimized infrastructure for training RL agents using Tensorflow.
- Unity ML Agents allows researchers and developers to create games and simulations using the Unity Editor and train them using Reinforcement Learning.
- Nervana Coach allows experimentation with state of the art Reinforcement Learning algorithms.
- Facebook’s ELF platform for game research.
- DeepMind Pycolab is a customizable gridworld game engine.
- Geek.ai MAgent is a research platform for many-agent reinforcement learning.
With the goal of making Deep Learning more accessible, we also got a few frameworks for the web, such as Google’s deeplearn.js and the MIL WebDNN execution framework. But at least one very popular framework died. That was Theano. In an announcement on the Theano mailing list, the developers decided that 1.0 would be its last release.
Learning Resources #
With Deep Learning and Reinforcement Learning gaining popularity, an increasing number of lectures, bootcamps, and events have been recorded and published online in 2017. The following are some of my favorites:
- The Deep RL Bootcamp co-hosted by OpenAI and UC Berkeley featured lectures about Reinforcement Learning basics as well as state-of-the-art research.
- The Spring 2017 version of Stanford’s Convolutional Neural Networks for Visual Recognition course. Also check out the course website.
- The Winter 2017 version of Stanford’s Natural Language Processing with Deep Learning course. Also check out the course website.
- Stanford’s Theories of Deep Learning course.
- The new Coursera Deep Learning specialization
- The Deep Learning and Reinforcement Summer School in Montreal
- UC Berkeley’s Deep Reinforcement Learning Fall 2017 course.
- The Tensorflow Dev Summit with talks on Deep Learning basics and relevant Tensorflow APIs.
Several academic conferences continued the new tradition of publishing conference talks online. If you want to catch up with cutting-edge research you can watch some of the recordings from NIPS 2017, ICLR 2017 or EMNLP 2017.
Researchers also started publishing easily accessible tutorial and survey papers on arXiv. Here are some of my favorites from this year:
- Deep Reinforcement Learning: An Overview
- A Brief Introduction to Machine Learning for Engineers
- Neural Machine Translation
- Neural Machine Translation and Sequence-to-sequence Models: A Tutorial
Applications: AI & Medicine #
2017 saw many bold claims about Deep Learning techniques solving medical problems and beating human experts. There was a lot of hype, and understanding true breakthroughs is anything but easy for someone not coming from a medical background. For an comprehensive review, I recommend Luke Oakden-Rayner’s The End of Human Doctors blog post series. I will briefly highlight some developments here.
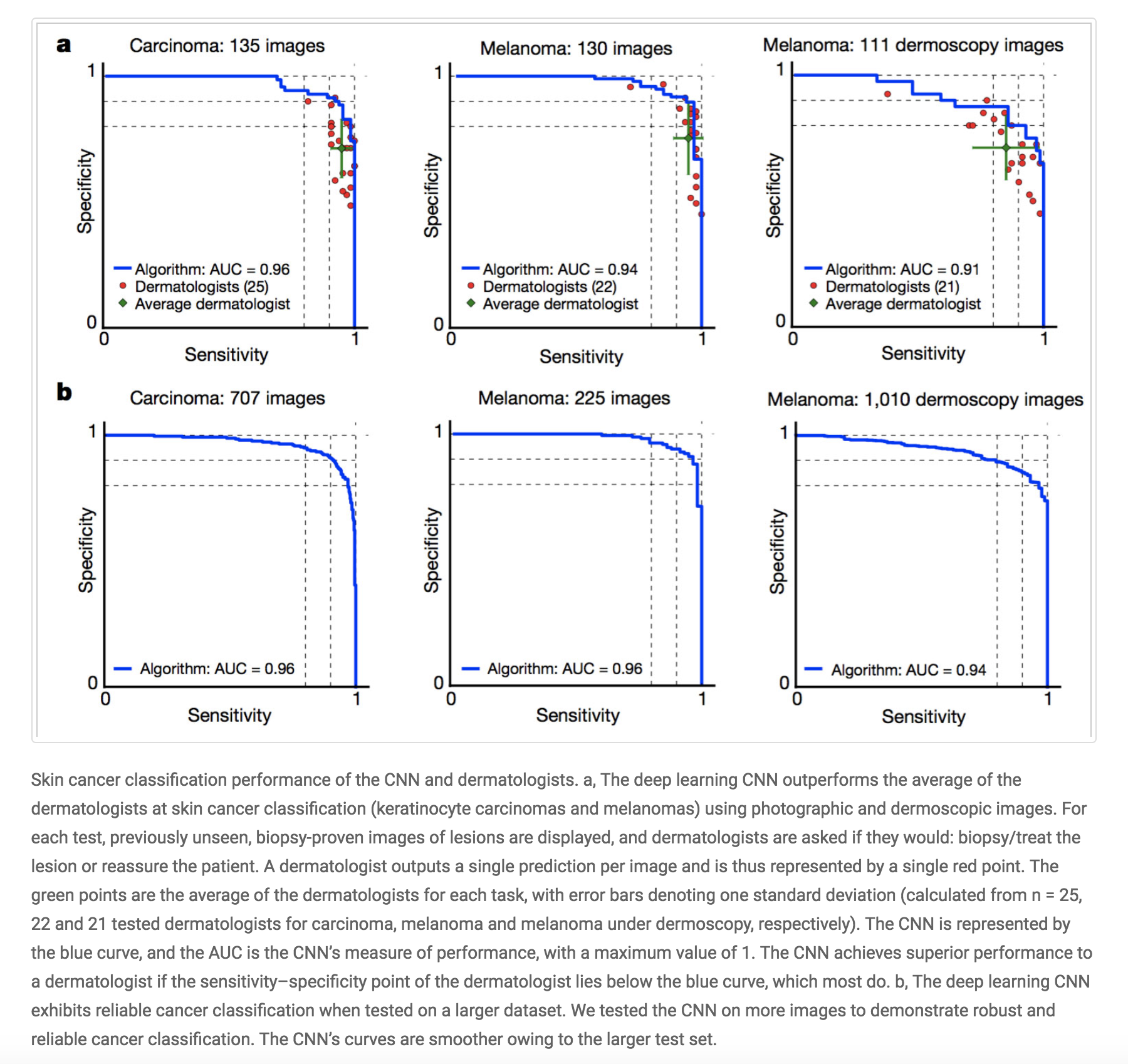
Among the top news this year was a Stanford team releasing details about a Deep learning algorithm that does as well as dermatologists in identifying skin cancer. You can read the Nature article here. Another team at Stanford developed a model which can diagnose irregular heart rhythms, also known as arrhythmias, from single-lead ECG signals better than a cardiologist.
But this year was not without blunders. DeepMind’s deal with the NHS was full of “inexcusable” mistakes. The NIH released a chest x-ray dataset to the scientific community, but upon closer inspection it was found that it is not really suitable for training diagnostic AI models.
Applications: Art & GANs #
Another application that started to gain more traction this year is generative modeling for images, music, sketches, and videos. The NIPS 2017 conference featured a Machine Learning for Creativity and Design workshop the first time this year.
Among the most popular applications was Google’s QuickDraw, which uses a neural network to recognize your doodles. Using the released dataset you may even teach machines to finish your drawings for you.
Generative Adversarial Networks (GANs), made significant progress this year. New models such as CycleGAN, DiscoGAN and StarGAN achieved impressive results in generating faces, for example. GANs traditionally have had difficulty generating realistic high-resolution images, but impressive results from pix2pixHD demonstrate that we’re on track to solving these. Will GANs become the new paintbrush?
Applications: Self-driving cars #
The big players in the self-driving car space are ride-sharing apps Uber and Lyft, Alphabet’s Waymo, and Tesla. Uber started out the year with a few setbacks as their self-driving cars missed several red lights in San Francisco due to software error, not human error as had been reported previously. Later on, Uber shared details about its car visualization platform used internally. In December, Uber’s self driving car program hit 2 million miles.
In the meantime, Waymo’s self-driving cars got their first real riders in April, and later completely took out the human operators in Phoenix, Arizona. Waymo also published details about their testing and simulation technology.
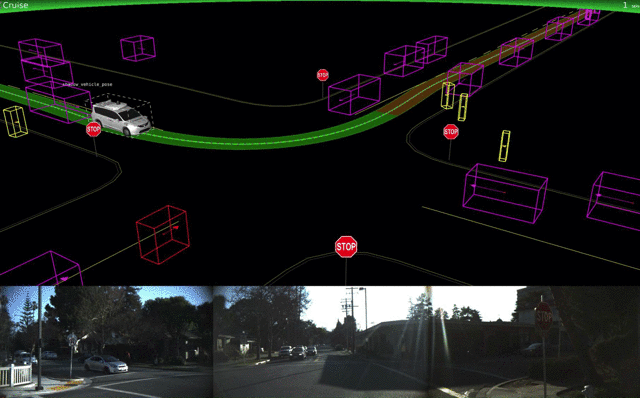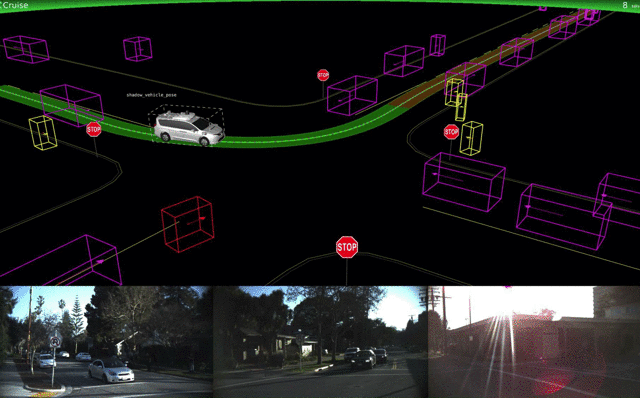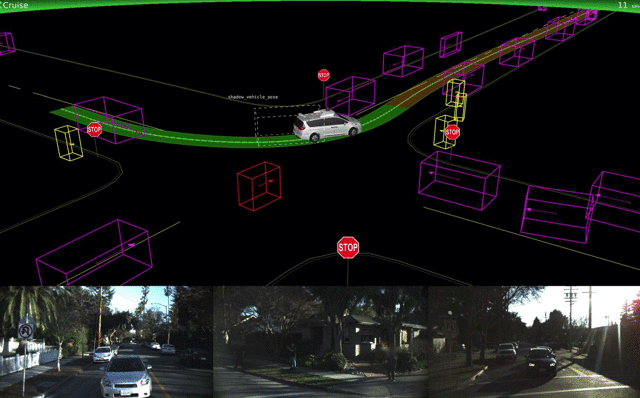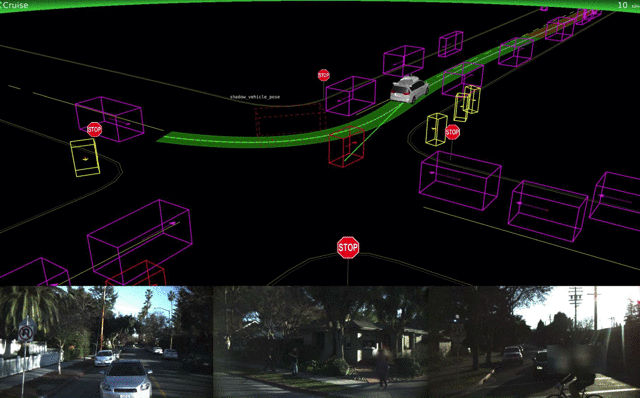
Lyft announced that it is building its own autonomous driving hard- and software. Its first pilot in Boston is now underway. Tesla Autpilot hasn’t seen much of an update, but there’s a newcomer to the space: Apple. Tim Cook confirmed that Apple is working on software for self-driving cars, and researchers from Apple published a mapping-related paper on arXiv.
Applications: Cool Research Projects #
So many interesting projects and demos were published this year that it’s impossible to mention all of them here. However, here are a couple the stood out during the year:
- Background removal with Deep Learning
- Creating Anime characters with Deep Learning
- Colorizing B&W Photos with Neural Networks
- Mario Kart (SNES) played by a neural network
- A Real-time Mario Kart 64 AI
- Spotting Forgeries using Deep Learning
- Edges to Cats
And on the more research-y side:
- The Unsupervised Sentiment Neuron – A system which learns an excellent representation of sentiment, despite being trained only to predict the next character in the text of Amazon reviews.
- Learning to Communicate – Research in which agents develop their own language.
- The Case for Learning Index Structures – Using neural nets to outperform cache-optimized B-Trees by up to 70% in speed while saving an order-of-magnitude in memory over several real-world data set.
- Attention is All You Need
- Mask R-CNN – A general framework for object instance segmentation
- Deep Image Prior for denoising, superresolution, and inpainting
Datasets #
Neural Networks used for supervised learning are notoriously data hungry. That’s why open datasets are an incredibly important contribution to the research community. The following are a few datasets that stood out this year:
- Youtube Bounding Boxes
- Google QuickDraw Data
- DeepMind Open Source Datasets
- Google Speech Commands Dataset
- Atomic Visual Actions
- Several updates to the Open Images data set
- Nsynth dataset of annotated musical notes
- Quora Question Pairs
Deep Learning, Reproducibility, and Alchemy #
Throughout the year, several researchers raised concerns about the reproducibility of academic paper results. Deep Learning models often rely on a huge number of hyperparameters which must to be optimized in order to achieve results that are good enough to publish. This optimization can become so expensive that only companies such as Google and Facebook can afford it. Researchers do not always release their code, forget to put important details into the finished paper, use slightly different evaluation procedures, or overfit to the dataset by repeatedly optimizing hyperparameters on the same splits. This makes reproducibility a big issue. In Reinforcement Learning That Matters, researchers showed that the same algorithms taken from different code bases achieve vastly different results with high variance:
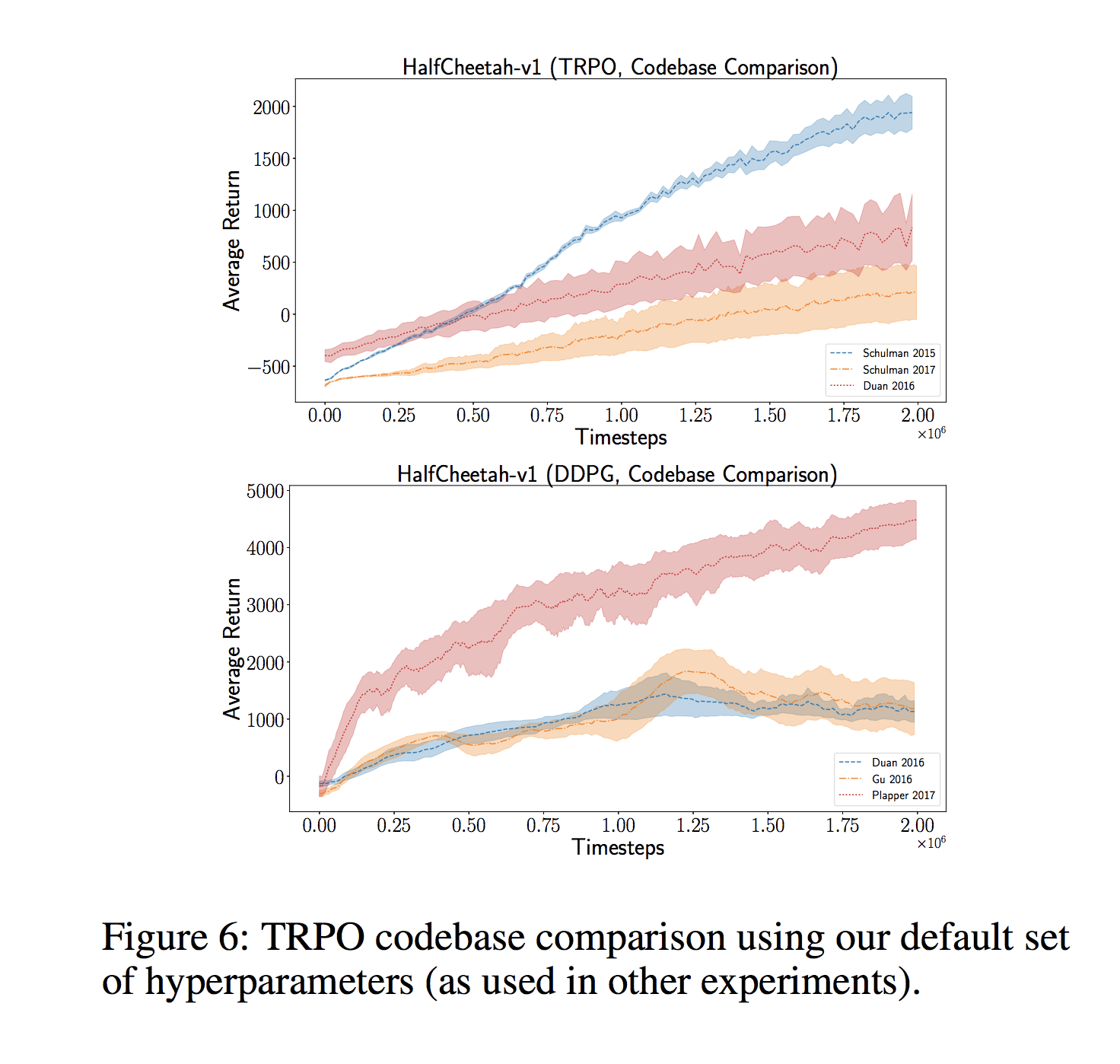
In Are GANs Created Equal? A Large-Scale Study, researchers showed that a well-tuned GAN using expensive hyperparameter search can beat more sophisticated approaches that claim to be superior. Similarly, in On the State of the Art of Evaluation in Neural Language Models, researchers showed that simple LSTM architectures, when properly regularized and tuned, can outperform more recent models.
In a NIPS talk that resonated with many researchers, Ali Rahimi compared recent Deep Learning approaches to Alchemy and called for more rigorous experimental design. Yann LeCun took it as an insult and promptly responded the next day.
Artificial Intelligence made in Canada and China #
With United States immigration policies tightening, it seems that companies are increasingly opening offices overseas, with Canada being a prime destination. Google opened a new office in Toronto, DeepMind opened a new office in Edmonton, Canada, and Facebook AI Research is expanding to Montreal as well.
China is another destination that is receiving a lot of attention. With a lot of capital, a large talent pool, and government data readily available, it is competing head to head with the United States in terms of AI developments and production deployments. Google also announced that it will soon open a new lab in Beijing.
Hardware Wars: Nvidia, Intel, Google, Tesla #
Modern Deep Learning techniques famously require expensive GPUs to train state-of-the-art models. So far, NVIDIA has been the big winner. This year, it announced its new Titan V flagship GPU. It comes in gold color, by the way.
But competition is increasing. Google’s TPUs are now available on its cloud platform, Intel’s Nervana unveiled a new set of chips, and even Tesla admitted that it is working on its own AI hardware. Competition may also come from China, where hardware makers specializing in Bitcoin mining want to enter the Artificial Intelligence focused GPU space.
Hype and Failures #
With great hype comes great responsibility. What the mainstream media reports almost never corresponds to what actually happened in a research lab or production system. IBM Watson is the poster-child over overhyped marketing and failed to deliver corresponding results. This year, everyone was hating on IBM Watson, which is not surprising after its repeated failures in healthcare.
The story capturing the most hype was probably Facebook’s “Researchers shut down AI that invented its own language”, which I won’t link to on purpose. It has already done enough damage and you can google it. Of course, the title couldn’t have been further from the truth. What happened was researchers stopping a standard experiment that did not seem to give good results.
But it’s not only the press that is guilty of hype. Researchers also overstepped boundaries with titles and abstracts that do not reflect the actual experiment results, such as in this natural language generation paper, or this Machine Learning for markets paper.
High-Profile Hires and Departures #
Andrew Ng, the Coursera co-founder who is probably most famous for his Machine Learning MOOC, was in the news several times this year. Andrew left Baidu where he was leading the AI group in March, raised a new $150M fund, and announced a new startup, landing.ai, focused on the manufacturing industry. In other news, Gary Marcus stepped down as the director of Uber’s artificial intelligence lab, Facebook hired away Siri’s Natural Language Understanding Chief, and several prominent researchers left OpenAI to start a new robotics company.
The trend of Academia losing scientists to the industry also continued, with university labs complaining that they cannot compete with the salaries offered by the industry giants.
Startup Investments and Acquisitions #
Just like the year before, the AI startup ecosystem was booming with several high-profile acquisitions:
- Microsoft acquired deep learning startup Maluuba
- Google Cloud acquired Kaggle
- Softbank bought robot maker Boston Dynamics (which famously does not use much Machine Learning)
- Facebook bought AI assistant startup Ozlo
- Samsung acquired Fluently to build out Bixby
… and new companies raising large sums of money:
- Mythic raised $8.8 million to put AI on a chip
- Element AI, a platform for companies to build AI solutions, raised $102M
- Drive.ai raised $50M and added Andrew Ng to its board
- Graphcore raised $30M
- Appier raised a $33M Series C
- Prowler.io raised $13M
- Sophia Genetics raises $30 million to help doctors diagnose using AI and genomic data